
برای دسترسی به رکورد قبلی و بعدی یک رکورد در SQL Server، میتوانید از توابع تحلیلی (Analytic Functions) مانند LEAD و LAG استفاده کنید. این توابع به شما اجازه میدهند که به سادگی به رکوردهای همسایه (قبلی و بعدی) در یک مجموعه داده دسترسی پیدا کنید.

- 690 بازدید
- 33

SQL Server هر مقدار رم موجود را برای بهبود عملکرد خود استفاده کند، مگر اینکه شما محدودیتی برای آن تعریف کنید. شما میتوانید با تنظیم محدودیت رم در SQL Server این رفتار را کنترل کنید
- 693 بازدید
- 19

این پارامتر تعیین میکند که SQL Server برای یک پرس و جو، چه سطح هزینهای (cost) را باید برای تصمیمگیری به استفاده از عملیات موازی (parallel execution) در نظر بگیرد. هزینه در اینجا به هزینه محاسباتی (از جمله زمان پردازش و منابع استفاده شده) برای اجرای یک پرس و جو اشاره دارد.
- 1228 بازدید
- 92

امروزه دسترسی سریع به داده های ذخیره شده در برنامه ها به یک امر حیاتی تبدیل شده است برنامه هایی برای اینکه بتوانند با فرکانس بالا داده ها بخوانند و ذخیره کنند دو انتخاب جذاب پیش رو دارند Redis و In-Memory OLTP
- 419 بازدید
- 66
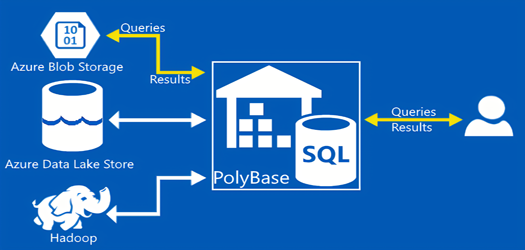
Polybase یک ویژگی در SQL Server است که به شما امکان می دهد داده ها را از منابع داده خارجی به SQL Server وارد کنید و از آنها در کوئری های T-SQL استفاده کنید. این ویژگی باعث می شود که بتوانید داده ها را از منابع مختلف مثل Oracle, Teradata, Mongo DB, cosmosDB و سایر منابع، بدون نیاز به کپی یا انتقال آنها به SQL Server ادغام کنید.
- 1088 بازدید
- 77

برخی ویژگی های جدیدی که به اس کیو ال 2022 اضافه شده در این مقاله مرور میکنیم
- 426 بازدید
- 29

محیط کاری SQL Server Management ، علاوه بر گزینه های اصلی و پرمخاطب ، نکات و ترفندهای زیادی را شامل می شود که شاید از آنها آگاهی نداشته باشید. نکاتی که دانستن آنها به افزایش بهره وری کار شما کمک می کند. در این مقاله ، ما نکاتی را عنوان می کنیم که می توانید در SSMS برای افزایش کارایی و کاهش زمان معمول خود استفاده کنید.
- 1732 بازدید
- 26

وقتی صحبت از بهینه سازی عملکرد کوئری ها برای کاهش زمان پاسخ به برنامه های وب در SQL میشود، اغلب شاهد تغییراتی در لایه برنامه یا ایندکس گذاری روی ستونهای جداول پایگاه داده هستیم و کمتر به بهینه سازی خود کوئری SQL توجه می شود. حتی معماران و توسعه دهندگان متخصص نیز فراموش می کنند که عملکرد پایگاه داده از داخل همین پرس و گاهی از نام پرس و جو باید شروع میشود. در اینجا هفت نکته ساده آورده شده است که عملکرد جستجوی SQL شما را افزایش می دهد.
- 1492 بازدید
- 42

SQL یکی از ابزارهای همه کاره در کار با دیتابیس های رابطه ای محسوب میشود. SQL حدود 40 سال پیش توسعه داده شد و بخاطر راحتی انجام عملیات CRUD در آن و کارایی بسیار بسرعت محبوب گشت. کم کم رقبا دیگر هم وارد میدان شدن و رقابت بین مایکروسافت با SQL Server؛ اوراکل با پایگاه داده اوراکل؛ و MySQL، توسعه یافته توسط Sun که در حال حاضر نیز متعلق به اوراکل است شروع شد. با این حال، اگر به عنوان خواننده ای متواضع در حوزه فن آوری باشید ممکن است بدانید که Big DATA افق روشنی دارد. چیزی که مسلم هست اینه که، برنامه های کاربردی داده های بزرگ حداقل در زمان های اخیر با الگوریتم MapReduce گوگل ایجاد شده اند و با سرعت فوق العاده ای در حال گسترش محصولات مختلف هستند. بطوری که حالا با یک جستجو در گوگل، می توانید تعداد زیادی از مقالات که مفاهیم Big DATA را بیان می کنند، پیدا کنید. کار با داده های حجیم باعث ایجاد و توسعه مفهمومی به نام NoSQL شد که قابلیت کار با حجم بسیار عظیمی از داده ها را داراست و در کار با داده ها به صورت بسیار ساده و روان از XML یا JSON استفاده میشود.
- 1602 بازدید
- 26
صفحه 1 از 2